How A/B Testing Can Be An Important Tool Which Offers You Results That Can Make a Difference


Analyzing A/B testing results may be the most important stage of a test. It’s also the least talked about. An A/B test’s usefulness depends entirely on your post-test analysis—was the test statistically significant? Replicable? Transferrable? To know whether to apply the results, you have to get into some A/B testing data science.
What is A/B testing?
A/B testing is an excellent way for businesses to predict and maximize their online impact. It refers to a randomized experiment process in which two or more versions of a page element are shown to different segments of visitors at the same time. This helps brands determine which version leaves the maximum impact and drives their business metrics.
With A/B testing, you can make data-backed decisions. It eliminates all the guesswork with website optimization. A is what is being tested before any changes are made. B is the variation of the original setup.
The variation of your website that moves your metric in the positive direction is the winner. Test new layouts and optimize your site to increase your business ROI with changes to these winning pages/elements.
How do you A/B test on a website?
A/B testing on a website isn’t so different from A/B testing in a mobile app. Select one or more variants of a button, image, message, or feature, and run a test to see how users react. To get started, simply select the element you want to test from within your A/B testing platform.
Step 1: Review your A/B test metrics
When a test ends, review the results. Depending on which A/B testing tool you’re using, you may get an email that the test is complete. If the interface is intuitive, it should clearly state whether the test was successful—that is, it ran as planned to the right sample of users.
If your test had a solid, provable hypothesis, such as pitting two landing pages against one another, you should be looking at one of three A/B test results:
- Option A won
- Option B won
- Inconclusive—neither won
(Tests with more variants, such as multivariate tests, will have more complex results.)
This is where most product teams go wrong: They apply the result and move on. But simply knowing which variant won in a head-to-head in a single test doesn’t always mean that that page, button, or feature is better. There are a few things you’ll have to check.
Warning: Beware A/B testing tools that automatically apply a winning variant. There’s lots to learn about your test before you can consider it valid.
Step 2: Ask, was this test valid?
Ensure that whatever result you’re about to share with others is in fact valid. Few things are worse than enshrining a principle in your product development process that’s based on correlation, not a causation.
For instance, telling the entire product team that pop-up messages increase sales when the real reason sales spiked during your test was unrelated—traffic from a post by a fashion influencer, say. And now the product team is overusing pop-ups.
Ask yourself:
- Was the test statistically significant? If you’re running your test on a sample of your entire user population, you always run into the question: Does what we’ve learned apply to all users? If it’s statistically significant, it does, with a small margin of error, and you can trust it. (If your A/B testing platform doesn’t calculate this for you, you’ll have to do it by hand.) If it’s not statistically significant, you can’t, and you’ll have to run the test with a larger sample.
- Were the samples representative? Even if enough users saw each of your variants, there could be significant differences between those populations. For example, if one variant was shown to a disproportionate number of users from a certain geography or on a certain device, it might not reflect all users. (An A/B testing platform with Random Sampling should take care of this for you.)
- Did it affect other metrics? Users don’t exist in a vacuum. Look to see what other effects the test had. For instance, if a push notification caused sales to rise, but unsubscribes to rise even more, is it worth it? Track the screen flow of your test cohort to make sure that a positive test result was actually net-positive for the business.
- Were there any user errors? It’s not uncommon for users to select the wrong image, mistype a message, or use a date in the wrong format, which can invalidate the test. Create a system of checks by enforcing user permissions in your A/B testing platform.
Of course, the unexpected can always strike. A bug can remove the checkout button, or users can react poorly to the new UI and demand the old one. You can minimize testing risk by staging your rollouts. Only expose, say, 10 percent of users to the new version, and only roll it out if it works.
“One of the most common mistakes product teams makes is selection bias. If users are allowed to opt into the test, or made aware that a test is happening (this happens with A/B testing platforms that have a flicker effect), it skews the results. That’s when you get a sample of only people that, say, like taking surveys, or think they’re getting a coupon.”
—Joe Corey, A/B Testing Data Science Expert
Step 3: Conduct more analysis
Numbers don’t always tell the clearest story. Consider the famous example of Anscombe’s Quartet, devised by a statistician to show how you can make one data set tell many stories depending on the chart you select. Below are four charts that all look quite different. But they’re all based off a set of statistics which look identical when viewed in a table.
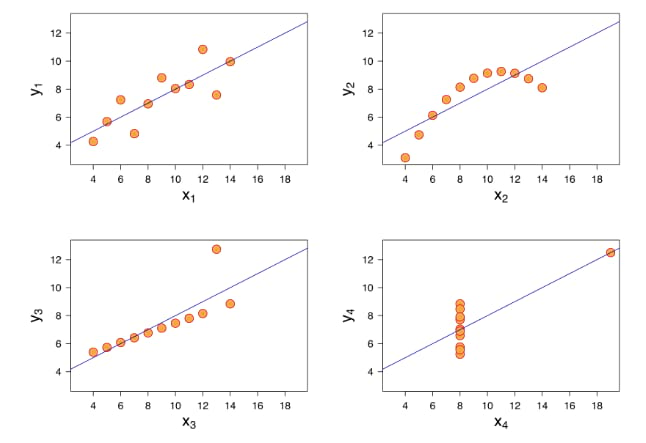
Visuals can convey highly complex relationships in large data sets that aren’t always apparent, and help you connect test back to larger business objectives.
Depending on your teams’ comfort level and data savviness, consider creating data visualizations. Someone trained in A/B testing data science may be able to do this by hand, but for the rest of us, there’s tools like Looker, Amplitude, and Tableau. They make data visualizations easy and accessible to everyone on the product and marketing team.
_____________________________________________________________
Read ‘The Ultimate Guide to A/B Testing‘
_____________________________________________________________
Step 4: Decide what to do next
Whatever the result of your test, you’re always left with the million-dollar question: Why? Why did this test have the effect that it did?
This is the art part of A/B testing science: Understanding your users’ psychology. If users completely ignore all variants of your push notification, perhaps they’re disinclined to push notifications in general. Or maybe the images in each variant weren’t significantly dissimilar. Based on what you know and data from past tests, which do you think is more likely?
Psychological insights (sometimes called qualitative data) are the basis of knowledge, which is how your team learns, shares, and develops better intuition.
Examples of A/B test results:
- Chick-fil-A learned that its customers prefer to pay with a credit card and made feature changes that increased mobile payments 6 percent.
- TodayTix learned its users are often in a rush, and miss the fine print. The team made its Rush and Lottery features easier to find and increased ticket sales 9 percent.
- Lottery.com learned that lottery players often don’t play with the expectation of winning, it reworded its landing page, and it increased click-throughs 60%.
Step 5: Share what you learned
Whatever you learned, as long as it’s valid, significant, and repeatable, your team should know. Record it in a testing log (usually just a shared doc) and bring it up at a biweekly check in, or quarterly review.
Make sure you capture all the proper data for each test:
- Description
- Stage of funnel
- User flow
- Goal
- Start and end date
- Hypothesis
- Key takeaways
This way, others will know what’s been tried before, what worked, and what didn’t work, and can build their tests with the benefit of your knowledge.
Pro tip: Don’t discount test results where your hypothesis was wrong. Negative results are just as valuable as positive ones. In the scientific world, where top scientific journals tend to mostly publish positive results, scientists spend untold millions of dollars accidentally replicating experiments that have already been performed. Don’t be like them.
How long should my A/B test run for?
In digital marketing and product management, two weeks is typical. After one week, check on your test. If it’s moved your key performance indicator (KPI) aggressively, perhaps more than you expected, you may make a decision to end it early, and scale, kill, or iterate upon it.
What can you A/B test?
You can A/B test everything on your website or mobile app. Make sure all of your content is optimized to its full potential. For instance, you want to make sure that every piece of content has the power to persuade and convert your audience into customers. This is especially true for types of content that can change your site visitors’ behavior or influence your business conversion rate.
Titles and headlines
The first thing that a visitor notices on your site is the headline. It sets the tone for how they’re feeling about your content. That’s why it’s crucial to pay attention to the headlines and subheadlines of your website.
When it comes to writing copy, you want them to be brief, clear, and compelling. Test out different fonts and styles to see which are most effective for converting your visitors.
Body text
Your website’s body should be written with your customer in mind. After all, it is the content most readers will interact with. The body should clearly state what is expected of visitors, and it should resonate with the page’s headline and subheadline. A well-written body can increase conversion rates for a website.
Navigation
Another element of your website worth A/B testing is navigation. It is very crucial to providing a great user experience. Make sure your plan for the site’s structure and link to different pages is clear and easy to understand.
Layouts
Website design and layout is the key to your success. Along with copy, images and videos can provide your online customer with everything they want to know about your products and services. When designing your product page, make sure you include all of the necessary information and test out the format that your product information, images, and videos are shown.
Start A/B testing fast with Taplytics: Learn more.